3. Dubletten- und Haushalte bearbeiten
3.1. Einführung
Die Bearbeitung ist unterteilt in die Schritte "Dublettensuche", "Dublettenzusammenführung" und "Haushaltsbildung". Diese Prozesse können automatisch in regelmässigen Intervallen oder manuell ausgelöst werden.
Das Ziel ist es Dubletten zu vermeiden und bereits bestehende Dubletten zu erkennen und zu entfernen. Mit der Haushaltsbildung sollen Personen die im selben Haushalt leben erkannt und durch erstellen von Beziehungen als Haushalt definiert werden.
3.1.1. Dublettensuche
Mit dem Job Dubletten, Haushalte suchen können wahlweise Dubletten für eine manuelle Bearbeitung gesucht und klassiert (Treffergenauigkeit "sehr hoch","hoch") werden oder eindeutige Dubletten gleich markiert und zusammengeführt werden. Weiter können Haushalte automatisch erkannt und gebildet werden.
3.1.2. Dublettenzusammenführung
Mit dem Job Markierte Dubletten zusammenführen werden Dubletten zu einer Person zusammengeführt.
3.1.3. Manuelle Bearbeitung
In der Ansicht Manuelle Bearbeitung können alle möglichen Dubletten und Haushalte manuell verknüpft werden.
3.1.4. Haushalterkennung
Die Methoden für die Erkennung von Haushalten ist bis auf den Vergleich der Vornamen identisch wie für die Dublettenerkennung.
3.1.5. Dublettenerkennung
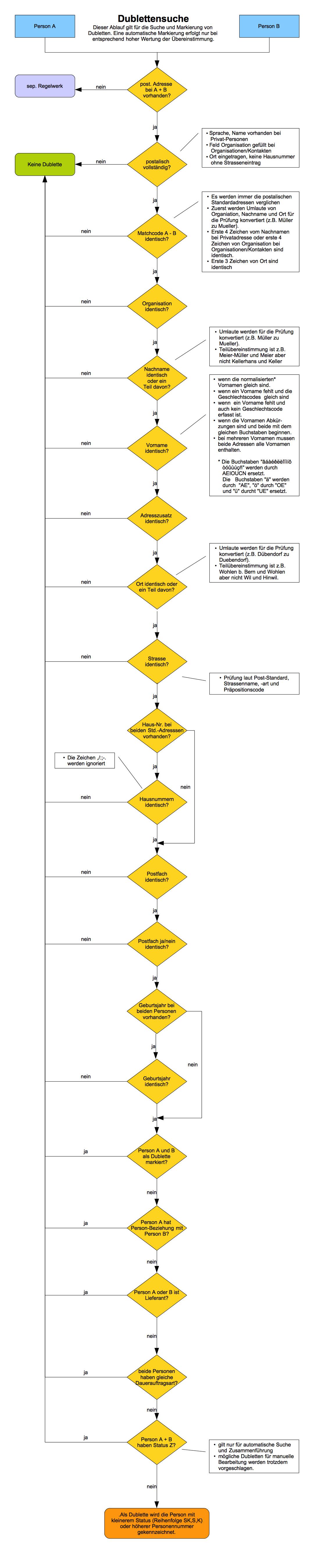
Im Flussdiagramm am Schkuss ist aufgezeigt, wie das System eine Person mit postalischer Adresse als Dublette erkennt.
3.1.5.1. Personen ohne postalische Adressen ("Mobile only")
Personen ohne postalische Adressen werden, gem. folgenden Kritrien automatisch als Dubletten erkannt:
die Adressen (E-Mail, Telefonnummer) müssen identisch sein
es werden Personendaten (Typ, Vorname, Name, Geburtsdatum, Geschlecht, Titel) und die Daten der postalischen Standardadresse (Land, PLZ, Ort, Strasse, Hausnummer) miteinander verglichen. Wenn bei einem der beiden Kandidaten Daten nicht vorhanden sind (z. B. keine postalische Adresse), gilt das als identischer Eintrag. Kleinere Abweichungen führen zu einer Reduktion der Wertung. Z.B. "H." statt "Hans" im Vornamen wird nicht mehr als "sehr hoch" gewertet und somit auch nicht automatisch zusammengeführt.
Nachfolgend 4 Beispiele:
Person A mit E-Mail + Vor- Nachname und Person B mit Vor-/Nachname, E-Mail abweichend:
| 1. Person | 2. Person | gleich? |
|---|---|---|
| Hans Muster | Hans Muster | ja |
| h.muster@bluewin.ch | hans.muster@bluewin.ch | nein |
Resultat: keine Dublette
Person A mit Name, post. Adresse und Person B nur mit E-Mail:
| 1. Person | 2. Person | gleich? |
|---|---|---|
| Hans Muster | ja | |
| Bahnhofstrasse 3 | ja | |
| 3604 Thun | ja | |
| h.muster@bluewin.ch | h.muster@bluewin.ch | ja |
Resultat: Vorschlag "mögliche Dublette"/"sehr hoch", automatische Zusammenführung möglich
Person A mit E-Mail + Vor-/Nachname und Person B mit E-Mail + Vor-/Nachname:
| 1. Person | 2. Person | gleich? |
|---|---|---|
| Hans Muster | Hans Muster | ja |
| h.muster@bluewin.ch | h.muster@bluewin.ch | ja |
Resultat: Vorschlag "mögliche Dublette"/"sehr hoch", automatische Zusammenführung möglich
Person A mit Name, post. Adresse und Person B mit E-Mail + Vorname gekürzt und Nachname:
| 1. Person | 2. Person | gleich? |
|---|---|---|
| Hans Muster | H. Muster | nein |
| Bahnhofstrasse 3 | ja | |
| 3604 Thun | ja | |
| h.muster@bluewin.ch | h.muster@bluewin.ch | ja |
Resultat: Vorschlag "mögliche Dublette"/"tief", keine automatische Zusammenführung